-
복합표본자료분석 - 3. EDA (R)R 2019. 12. 28. 20:47
이전 포스트에서 EDA에 대해 다루려 했는데, 예제 논문을 따라가다 보니 너무 큰 문제가 보여 더 이상 진행하는 게 의미가 없어 도중에 중단했다. 사실 이런 경우는 굉장히 흔한데, 예상치 못한 일이 발생한 경우 무시하고 넘어가는 것보다 문제를 해결할 방법을 고민하거나 도저히 안 되겠는 경우 중단하는 게 차라리 낫다. 그런 이유로 해외 논문 중 먼저 만들어 놓은 자료를 이용할 수 있는 논문을 찾아서 EDA과정부터 다시 진행해 보려고 한다.
위 논문은 수면시간과 비만에 관한 연구이다. 위 링크를 통해 들어가보면 논문 원문을 무료로 다운로드할 수 있으니 참고하고 싶으면 들어가 보자. 위의 연구는 미국 NHANES 자료를 분석해서 만든 연구이다. 연구 초기에는 잘 된 연구를 재현해보는 것도 충분히 도움이 되며, 미국 연구 결과가 한국인에게도 동일한 결과를 보이는지 (흔히 말하는 in Korean 연구)도 해외 저명 학술지라면 몰라도 국내 학술지에는 충분히 실릴 수 있는 연구기 때문에 배우는 과정에서는 굉장히 좋은 주제이다. 다만 위의 연구는 오랜 시간의 자료를 세로 결합한 후 향후 추적관찰을 통해서 트렌드에 대한 분석까지 진행했는데... KNHANES는 추적관찰을 하지 않았을 뿐 아니라 세로 결합하기도 좀 귀찮기도 하고... 해서 먼저 만들어 놓은 2016년 자료만을 이용해서 분석하기로 마음먹었다.
이전 포스트에서도 언급했던 내용이지만, 복합 표본형태를 가지는 자료를 분석할 때에는 개인적으로 EDA과정까지는 일반적인 통계 분석법을 사용하는 것을 선호한다. 아무래도 복합표본 분석법 만을 사용하면 불편한 점이 있기 마련이다. 논문에 들어가는 수치나 그림은 당연히 복합표본 분석을 사용해야겠지만 EDA과정에서는 그렇게 까지 까다로울 필요는 없다 생각한다.
1. 변수 확인
예제 논문의 변수 구성은
Y변수: 비만
X변수: 자가 설문을 통한 수면시간
covariates: 우울점수, 신체활동 정도, 교육 수준, 인종, 음주, 흡연, 성별, 밤에 자다 깨는지, 낮동안 졸리는지, 나이...
인데 KNHANES에는 없는 설문도 있으니 적당히 넘어가자.
1) Y변수: 비만
비만의 지표로 가장 흔히 사용하는 게 BMI이다. 근데 연구에 BMI를 다룰 때 주의할 사항이 몇 개 존재한다. 그 첫 번째가 역설적이지만 BMI는 비만을 제대로 반영하지 못한다는 것이다.
예를 하나 들자면,
키 188cm, 몸무게가 113Kg인 사람이 있다.
이 사람의 BMI를 계산해 보면 113/(1.88²)= 31.97로 비만이다.
이 사람이 누군가 하면...
더보기
전성기의 주지사님이시다. 진짜로 비만 맞을까?
이런 이유로 BMI는 인구 전체의 비만 동향을 알아볼 때에만 써야지 BMI만을 가지고 비만을 진단해서는 안된다고 하기는 하는데, 실제로는 BMI만 가지고 비만을 진단하는 경우가 흔하다. 따라서 엄격하게는 비만을 진단하기 위해서는 BMI보다는 허리둘레가 더 유용하다. 하지만 해외 논문의 경우 비만을 진단하는 용도로 BMI가 더 흔하게 사용되며, 예제 논문에서도 역시 BMI를 기준으로 사용하고 있다. 이런 경우 원 논문과의 통일성을 더 중요하게 여길 건지, 아니면 내 연구의 단독적인 완성도를 높일 건지 고민을 해야 한다.
두 번째 주의할 점은 비만의 WHO 기준과 한국의 기준이 다르다는 점이다.

대한 비만학회의 기준은 BMI 25를 비만으로 정의하고 있는데 문제는 이렇게 정의하면 비만인구가 너무 늘어난다. 그리고 더 중요한 문제는 연구결과가 좋지 못할 가능성이 있다. 대부분의 관찰연구들에서 BMI와 adverse outcome들의 관계는 J shape를 그리고 있다. 문제는 한국인을 대상으로 한 관찰연구들에서 BMI 25근처에서 최적의 건강상태를 보이고 있다는 점이다. 따라서 BMI 25를 비만의 기준으로 삼게되면 건강한 사람들이 비만 집단에 포함되게 되어 좋은 연구결과를 얻을 수 없게 된다. 이런 문제를 해결하기 위해 원래의 대한비만학회 기준은 비만의 진단을 위해 허리둘레를 같이 사용하도록 권장하고 있지만... 실제로는 그냥 BMI 25 얘기만 있지 허리둘레는... 그리고 이리 복잡하게 할 거면 차라리 처음부터 허리둘레만 사용하는 게 더 편하다. 마지막으로 해외 논문에 낼 거면 WHO 기준인 BMI 30이 그네들 눈에는 더 익숙하다. 원 논문도 BMI 30이 기준이기도 하고...



이전 포스트 결과에서 계속 진행해보면 BMI 30 이상은 330명이다. 대상자 수가 좀 팍 줄어드는 느낌이 있기는 하지만... 그래도 망할 정도는 아니니...


아무리 봐도 허리둘레 기준이 낫기는 하다.
어차피 논문에 실을 것도 아니니 허리둘레 기준(남자 90cm, 여자 80cm 이상) 비만으로 정의하고 진행하자.
hn16$obesity <- ifelse(hn16$sex==1&hn16$HE_wc>=90, 1, ifelse(hn16$sex==2&hn16$HE_wc>=80,1,0)) table(hn16$obesity,useNA = "always")
2) X 변수: 자가 설문을 통한 수면시간
자가 설문을 통한 수면시간


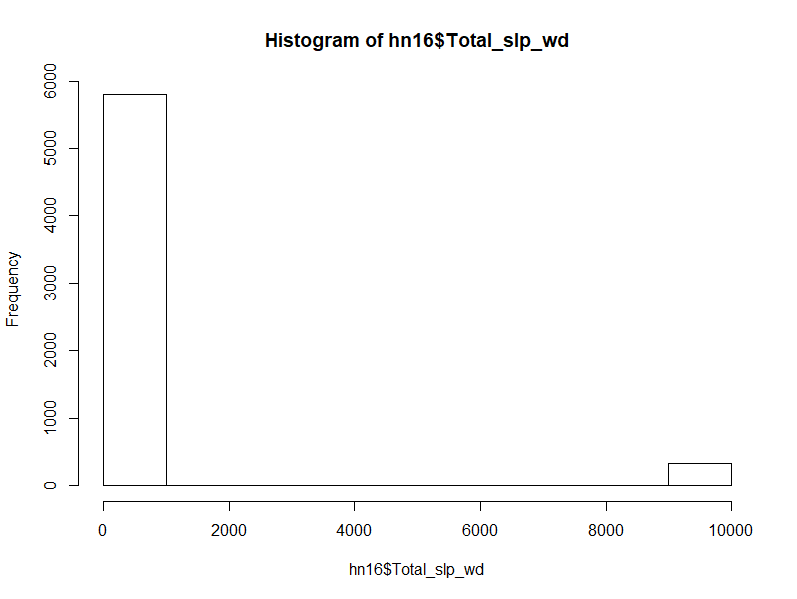
국건영 자료의 경우 무응답자를 8888, 9999와 같은 식으로 표현하는 경우가 흔하다. 수면시간의 경우도 무응답자를 9999로 처리했으며 이를 다른 고려 없이 처리한다면 하루 166시간을 자는 사람들이 출현하게 된다. 코딩 설명서를 잘 살펴보면 그런 일이 없을 텐데... 문제는 제대로 보지 않고 그대로 진행하는 경우 생긴다. 이 부분을 처리하고 진행하면
hn16$sleep <- ifelse(hn16$Total_slp_wd==9999, NA, round(hn16$Total_slp_wd/60,0)) table(hn16$sleep,useNA = "always") hist(hn16$sleep)

얼추 정규분포 비슷하게 보이는 모습을 확인할 수 있다.
그리고 주중 수면시간과 주말 수면시간을 어떻게 처리할지 고민할 필요도 있다. 상식적으로 생각해봐도 주중에 수면시간이 부족하면 주말에 몰아서 잔다던가... 하는 부분들을 고려해 봐야 할 것 같지만... 예제를 위해 그렇게까지 하기에는... 귀찮으니 주중 수면시간으로 퉁치고 넘어가는 게 좋을 것 같다.
3) Covariates
보정변수를 잘 결정하는 것이 연구의 성패를 가름하는 가장 중요한 요소 중 하나이다. 예를 들어 주머니에 라이터의 존재여부(X)에 따른 폐암으로 사망 여부(Y)를 분석한다고 해보자. 우리는 이미 주머니에 라이타가 있다는 것이 흡연여부를 반영하는 내용이며, 흡연의 영향으로 폐암 사망 확률이 올라간다는 것을 알고 있지만 단순히 통계 프로그램에 두 변수를 넣고 분석한다면 통계적으로 유의하다는 결과를 보여줄 것이다. 이러한 문제를 해결하기 위해서 필요한 것이 혼란변수 보정이다. 만약 분석할 때 흡연여부를 covariate(보정변수, 혼란변수, 공변량...)로 넣고 분석한다면 라이타의 유무에 따른 폐암의 확률을 분석할 때 흡연의 영향력을 어느 정도 보정해 줄 수 있다(어디까지나 어느 정도이다. 완벽하게 없애 주지는 못한다.). 반대의 경우도 있다. 흡연(X)에 따른 폐암 발생 확률(Y)을 분석한다고 했을 때 라이터의 소지 여부를 공변량으로 두면 안된다. 왜냐하면 폐암 발생에 대한 흡연의 영향력을 라이타 소지 여부가 갉아먹기 때문이다(앞의 어느 정도.. 내용의 연장. 두 변수가 밀접히 연관되어 있으면 통계적 분석 결과는 갈라먹기의 양상을 보여준다.). 따라서 보정변수를 결정하기 위해서는 기존 연구들에서 보여준 인과관계 및 기존 연구들의 선례를 고찰하고 그대로 따를 필요가 있다.
만약 기존 연구를 참조하는 것이 불가능하다면...
a) 기본 SES 변수
; 성별, 나이, 소득 수준, 교육 수준... 어느 논문에나 기본적으로 들어가는 공변량이다. 이 변수 들은 양쪽 집단의 연구 대상이 균질한지 판단할 수 있게 해 주며, 미세한 차이를 보정해 줄 수 있다(이해 안 간다면...).
b) X 및 Y에 영향을 줄 수 있는 변수
; 기존 연구들을 뒤져서 라이터 소지(X)에 관련된 요소 및 폐암 발생에 관련된 요소(Y)에 관련된 변수들을 보정변수로 고려해야 한다. 연구 초보자들이 흔히 하는 실수 중 하나가 reference citation에 매우 인색하다는 점이다. 그런데 사실 연구를 진행하려면 다른 연구들을 참고해야만 하는 부분들이 너무나 많다. 비슷한 주제를 다룬 논문들을 볼 때 결론만 볼 것이 아니라 어떤 보정변수를 어떤 이유로 골랐는지에 대한 고민이 필요하다.
c) 다중공선성 문제
; 중요하다는 이유로 보정변수로 상관관계가 큰 변수들을 마구 투입해서는 안된다. 가장 흔한 예가 비만 여부를 보정한답시고 BMI와 허리둘레를 같이 보정변수로 넣는 경우가 있다. 이렇게 하면 다중공선성 문제를 일으켜 결과를 꼬이게 만들 수 있다. 이를 해결하는 몇 가지 방법이 있기는 하지만 의학논문 영역에서 쓰기는 힘든 방법들이니 크게 고민 말고 보정변수 중 상관관계가 크거나 다변수 분석에서 다중공선성을 보이는 경우 더 중요해 보이는 하나의 변수만 투입하자.
d) 인과관계 문제
; 아까 라이터 문제의 연속이다. 예제의 경우 수면시간(X)에 따른 비만(Y)의 문제이다. 여기서 가장 중요한 보정변수는 우울증의 여부이다. 우울증은 수면시간과도 연관이 있고 비만에도 연관이 있다. 인과관계를 보면 만약 우울증이 수면장애의 가장 중요한 원인이라면 우울증→수면장애→비만 일 것이며 이 경우 수면장애는 우울증을 반영하는 지표이기 때문에 연구의 의미가 사라진다. 반대로 수면장애→우울증→비만 일 경우 연구는 의미를 갖는다. 사실 인과관계의 고민은 굉장히 힘든 영역이며 이렇게 이 주제를 언급하면서도 아직 잘 모르는 부분이 너무 많다. 더욱이 실제의 인과관계는 우울증⇆수면장애⇆비만⇆우울증 의 형태일 것이기 때문에 이를 어떤 식으로 다룰 것인지 많은 고민이 필요한데... 따라서 선행연구들을 보면 된다. 내가 모든 걸 다 고민할 필요는 없다. 앞에 나보다 더 뛰어난 사람들이 실컷 고민하고 그 결과가 논문이니 나도 확실한 의지가 없다면 앞의 결과를 따라도 좋다.
하여간 가장 중요한 보정변수는 우울증 점수이다. PHQ-9에 대해서는 이전 포스트에서 다룬 바 있으니 그걸 참고하고... 여기에 추가로 나이와 성별, 교육 수준, 소득 수준 만을 추가로 보정해 보자.
library(dplyr) aa <- hn16 %>% select(ID,psu,kstrata,wt_itvex,sex,age,ho_incm5,edu,mh_PHQ_S,DF2_pt,obesity,sleep) aa <- na.omit(aa) head(aa)
→ 이번 예제를 분석하면서 결측치를 가진 자료는 모두 삭제한 후 분석할 예정이다. 국건영 분석자료집에서는 결측치가 있어도 대상을 삭제하지 말라고 하고 있으나... 쓰지 않을 자료를 왜 남겨놔야 하는지 솔직히 이유를 모르겠다. 더욱이 R의 survey package에서는 weight변수에 결측이 있는 경우 분석을 할 수 없게 되어 있다. 따라서 예제에서는 결측을 가진 모든 관측치를 날려버리고 분석을 진행할 예정이다.
2. 단변수 EDA
1) 성별
성별은 중요한 보정변수 중 하나이다. 분석을 하다 보면 남자와 여자는 서로 다른 면이 상당이 많다. 따라서 성별에 따른 차이를 인식하는 것이 중요한 경우가 많다. 그리고 더 중요한 것은 성별이 그 자체로는 의미가 없더라도 타 변수와의 상호작용을 통해 유의한 경우도 많다는 점이다. 따라서 상호작용에 대한 고려도 해야 한다.
단변수 EDA에서는 X변수와 Y변수를 결과변수로 놓고 관계를 파악한다. 논문에 실리는 결과는 Y변수와의 관계이지만 전체적인 막락을 파악하기 위해서는 X변수와의 관계도 중요하다.
library(ggplot2) aa %>% ggplot(aes(sleep))+geom_histogram(bins = 10)+facet_wrap(~factor(sex)) m0 <- lm(sleep~factor(sex),data=aa) summary(m0) m1 <- glm(obesity~factor(sex),family = binomial(),data=aa) summary(m1) round(exp(cbind(coef(m1),confint(m1))),3)
육안으로 확인했을 때 성별에 따른 수면시간(X)은 큰 차이를 보이지 않는다.

그런 모습은 선형 회귀분석 결과에서도 보이고 있다.

그에 비해, 성별에 따른 비만 정도는 차이를 보이고 있다. 여성이 비만일 확률이 1.89 (95% CI: 1.70-2.01)배 높다. 문제는 비만의 정의가 남성의 경우 허리둘레 90, 여성의 경우 80 기준이기 때문에 이 결과는 그러한 차이를 반영하는 모습이라고 보면 될 것 같다. 성별에 따른 비만의 차이는 지금은 그냥 넘어가지만 나중에는 뭔가 조치를 취해야 할 내용이다. 남녀를 따로 분석한다던가... 성별을 민감도 분석에 투입한다던가...
2) 나이
나이에 따른 수면시간은
aa %>% ggplot(aes(factor(round(age/5)*5),sleep))+geom_boxplot() m3 <- gam(sleep~s(age), data=aa) plot(m3)

나이에 따른 수면시간을 보면 위의 boxplot에서나 아래의 일반 가법 모형 결과에서나 나이가 증가함에 따라 수면시간은 점차 줄어들다가 60세 이후에 안정되는 모습을 보여주고 있다.
나이에 따른 비만 확률은,
aa %>% ggplot(aes(factor(round(age/5)*5),obesity))+stat_summary(fun.data= mean_se,geom = "pointrange") m4 <- gam(obesity~s(age), family=binomial, data=aa) plot(m4)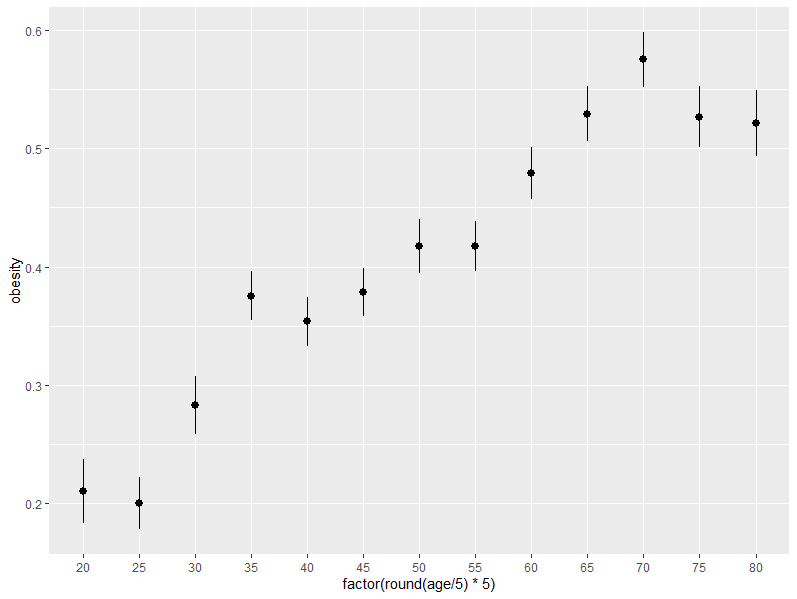

나이가 증가함에 따라 증가하는 모습을 볼 수 있다.
위의 두 가지 결과를 확인해 봤을 때 나이는 X변수 및 Y변수에 모두 관여하는 변수로 적절히 보정하지 않으면 양질의 연구결과를 보장할 수 없게 된다. 이런 이유로 원 논문에서도 나이와 성별에 따라 민감도 분석을 시행하였다.
그리고 실제 논문에서는 일반가법모형을 사용할 수 없기 때문에 적절한 단위로 잘라서 카테고리화 하는 것이 합리적이다. 그 단위를 얼마로 자를 것인가는 연구자마다 다르겠지만 위의 그림을 얼추 봐도 10 단위로 자르는 것은 너무 넓어 보인다. 따라서 5 단위로 잘라 사용해보자.
aa$age_cate <- factor(round(aa$age/5)*5) table(aa$age_cate) aa$age_cate <- relevel(aa$age_cate, ref = "20")3) 소득 수준
국건영에서 소득 관련 변수로 가계소득 4 분위, 5분위, 그리고 연속변수 형태의 월 소득이 있다. 정보량은 연속변수 형태의 월 소득이 가장 많겠지만 여기서는 편의 상 5분위 소득변수를 사용하려 한다. 4분위 변수를 사용해도 되겠지만 대상자의 수가 어느 정도 되기 때문에 구태여 정보의 양을 줄일 필요는 없다.
aa %>% ggplot(aes(factor(ho_incm5),sleep))+geom_boxplot() m5 <- lm(sleep~factor(ho_incm5), data=aa) summary(m5)

시각적으로 명확한 양상을 보이지는 않지만 통계적으로는 소득 수준이 높으면 수면 시간이 길어짐을 알 수 있다.
aa %>% ggplot(aes(factor(ho_incm5),obesity))+stat_summary(fun.data= mean_se,geom = "pointrange") m6 <- glm(obesity~factor(ho_incm5), family=binomial, data=aa) summary(m6)

소득 수준과 비만의 관계는 좀 더 명확하다. 소득 수준이 높을수록 수면시간은 길어지면서 비만의 확률은 낮아진다. 따라서 본 분석에서 소득 수준을 제대로 보정하지 않은 경우 수면시간에 따른 비만의 영향을 과대평가할 수 있다.
aa$ho_incm5 <- factor(aa$ho_incm5) aa$ho_incm5 <- relevel(aa$ho_incm5, ref = "1")4) 교육 수준
교육 수준도 소득과 비슷한 양상을 보인다.
aa %>% ggplot(aes(factor(edu),sleep))+geom_boxplot() m7 <- lm(sleep~factor(edu), data=aa) summary(m7) aa %>% ggplot(aes(factor(edu),obesity))+stat_summary(fun.data = mean_se,geom = "pointrange") m8 <- glm(obesity~factor(edu), family=binomial, data=aa) summary(m8)



aa$edu <- factor(aa$edu) aa$edu <- relevel(aa$edu, ref = "1")5) 우울증 점수
우울증은 수면시간과 체중에 중요한 영향을 미치는 변수이다. 이전 포스트에서 다뤘듯이 2016년 국건영에는 우울증 설문인 PHQ-9이 포함되어 있다(mh_PHQ-S). 여기에 현재 우울증 치료 여부(DF2_pt)를 추가해서 분석해 보자.
aa %>% ggplot(aes(factor(floor(mh_PHQ_S/5)*5),sleep))+geom_boxplot() aa %>% ggplot(aes(factor(DF2_pt),sleep))+geom_boxplot() m9 <- lm(sleep~factor(floor(mh_PHQ_S/5)*5)+factor(DF2_pt), data=aa) summary(m9) aa %>% ggplot(aes(factor(floor(mh_PHQ_S/5)*5),obesity))+stat_summary(fun.data = mean_se,geom = "pointrange") aa %>% ggplot(aes(factor(DF2_pt),obesity))+stat_summary(fun.data = mean_se,geom = "pointrange") m10 <- glm(obesity~factor(floor(mh_PHQ_S/5)*5)+factor(DF2_pt), family=binomial, data=aa) summary(m10)





우울점수 및 현재 우울증 치료 유무는 수면시간과는 유의한 관계를 가지고 있었지만 비만에는 영향을 미치지 않고 있다. 어째 처음 생각과는 좀 다른 것 같기는 하지만... 변수를 다시 정리해보면 PHQ-9 score는 0~9점 (robust), 10점 이상(우울증 의심)으로 끊을 수 있고, 이것을 DF2_pt 변수에 따라 확인해 보면,

PHQ-9이 10점 이상인 사람 중 271명은 우울증 진단을 받은 적이 없으며 33명은 진단은 받았으나 치료는 X, PHQ-9이 10점 미만인 대상자 중에서도 111명은 이전에 우울증 진단을 받은 적 있으며, 78명은 현재 치료 중이다. 이를 한 변수로 묶어 보자면 아래와 같을 것이다.
aa$depression <- interaction(aa$mh_PHQ_S>=10,aa$DF2_pt) aa$depression <- relevel(aa$depression, ref = "FALSE.8")6) X와 Y변수
원래 제일 먼저 봐야 할 변수인데 어찌하다 보니 뒤로 밀렸다.
aa %>% ggplot(aes(factor(sleep),obesity))+stat_summary(geom = "pointrange")
언뜻 보기에는 J-shape모양으로 볼 수도 있지만, 5시간 미만과 11시간 이상은 대상자 수가 부족해서 se를 나타내는 error bar의 길이가 늘어나 있는 것을 확인할 수 있다. 이 부분을 고려한다면 수면 시간이 늘어남에 따라 비만 확률이 완만히 감소한다고도 볼 수 있다. 5시간 미만과 11시간 이상의 극단치를 각각 하나의 군으로 묶어서 처리하는 것이 좋을 것 같다.
aa$sleep <- ifelse(aa$sleep<=5, 5, ifelse(aa$sleep>=11, 11, aa$sleep)) table(aa$sleep)
3. 상호작용
다음 단계는 상호작용을 고려한 분석이다. 3 변수 이상의 원인 변수의 상호작용을 파악하는 것은 분석이야 그렇다 치더라도 결과를 해석하기 어렵기 때문에 우선 X변수를 제외한 2개의 원인변수 간의 상호작용 분석으로 시작한다.

sex age_cate ho_incm5 edu depression sex X X X X X age_cate X X X X ho_incm5 X X X edu X X depression X 위의 표는 X변수 및 covariate들을 늘어놓은 표이다. 표의 빈칸에 들어갈 상호작용을 분석하면 된다.
1) age_cate * sex
m0 <- glm(obesity~sex*age_cate, data=aa, family = binomial()) summary(m0)
상호작용 term이 유의함을 알 수 있다. 상호작용의 해석은 위와 같이 결과가 한 화면 가득일 때 해석이 힘들어진다. 이런 경우 그림을 이용하면 쉽게 이해할 수 있다.
df <- expand.grid(sex=1:2, age_cate=seq(20,80,by = 5)) df$sex <- factor(df$sex) df$age_cate <- factor(df$age_cate) df$pred <- predict(m0,type = "response",newdata = df) df %>% ggplot(aes(age_cate, pred, group=sex, col=sex))+geom_line()
대략 50대까지는 나이에 따른 남녀의 비만 비율이 비슷하지만 50대 이후 차이를 보인다.
이런 식으로 눈으로 봐도 유의한 경우 나중에 X변수와의 상호작용을 추가한 분석을 고려한다. (sex*age_cate*sleep)
2) ho_incm5*sex
m0 <- glm(obesity~sex*ho_incm5, data=aa, family = binomial()) summary(m0) df <- expand.grid(sex=1:2, ho_incm5=1:5) df$sex <- factor(df$sex) df$ho_incm5 <- factor(df$ho_incm5) df$pred <- predict(m0,type = "response",newdata = df) df %>% ggplot(aes(ho_incm5, pred, group=sex, col=sex))+geom_line()

소득에 따른 비만비율도 성별에 따른 차이가 있다.
3) edu*sex
m0 <- glm(obesity~sex*edu, data=aa, family = binomial()) summary(m0) df <- expand.grid(sex=1:2, edu=1:4) df$sex <- factor(df$sex) df$edu <- factor(df$edu) df$pred <- predict(m0,type = "response",newdata = df) df %>% ggplot(aes(edu, pred, group=sex, col=sex))+geom_line()

4) depression*sex
m0 <- glm(obesity~sex*depression, data=aa, family = binomial()) summary(m0) df <- expand.grid(sex=1:2, depression=unique(aa$depression)) df$sex <- factor(df$sex) df$depression <- factor(df$depression) df$pred <- predict(m0,type = "response",newdata = df) df %>% ggplot(aes(depression, pred, group=sex, col=sex))+geom_line()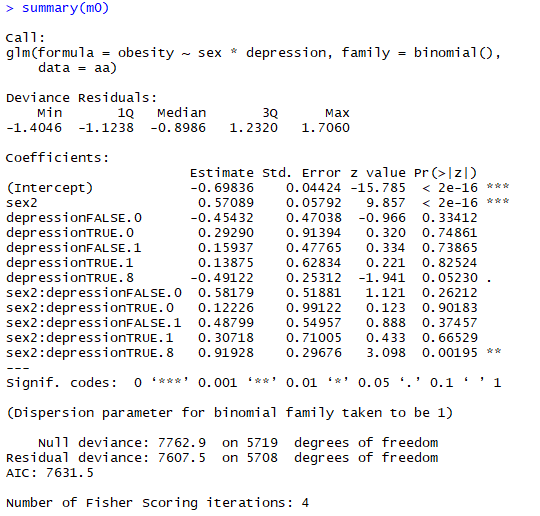
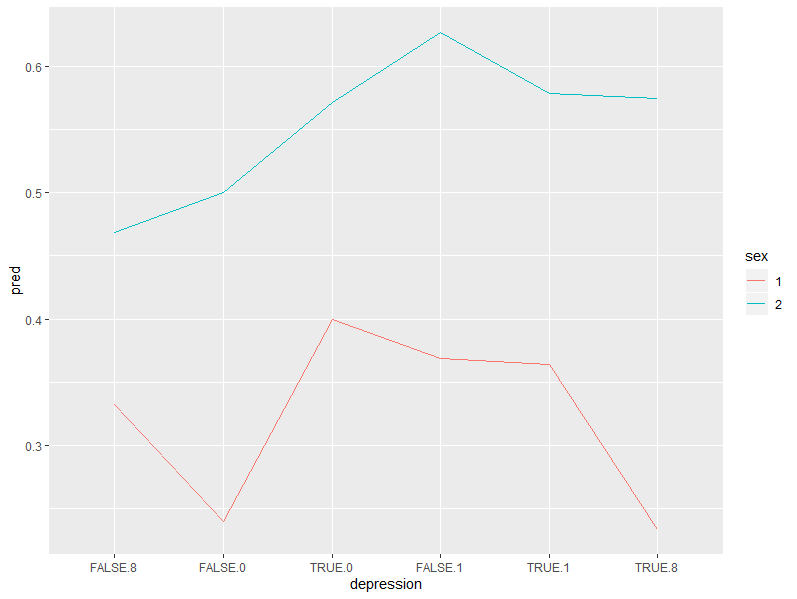
우울증과 성별의 상호작용은 통계적으로는 유의하지만 다른 상호작용에 비해 그다지 드라마틱하지 못하다. 우선 keep 해두고 있겠지만 나중에 식이 복잡해지면 구태여 넣을 필요 없어 보인다.
5) ho_incm5*age_cate, edu*age_cate, depression*age_cate --> 유의하지 않음
6) edu*ho_incm5 (keep), depression*ho_incm5 --> 유의하지 않음
7) edu*depression --> 유의하지 않음
결과적으로 봤을 때 성별에 관련된 상호작용만 유의한 양상을 보였다. 이런 경우 성별에 대한 상호작용을 원천적으로 없애는 방법은 남/녀 따로 분석하는 방법이 있다. 이렇게 하게 되면 상호작용에 대해 분석하거나 해석할 필요가 없어지는 장점이 있지만, 결과표가 2개 생기며 남녀의 결과가 다른 이유를 묻는 리뷰어에게 설명을 해야 할 필요가 생긴다.
4. 다변수 분석
aa$sleep <- factor(aa$sleep) aa$sleep <- relevel(aa$sleep, ref = "8") m0 <- glm(obesity~age_cate+ho_incm5+edu+depression+sleep, data=subset(aa,sex=="1"), family = binomial()) summary(m0) round(exp(cbind(coef(m0),confint(m0))),3) m1 <- glm(obesity~age_cate+ho_incm5+edu+depression+sleep, data=subset(aa,sex=="2"), family = binomial()) summary(m1) round(exp(cbind(coef(m1),confint(m1))),3)
위의 예제는 남자의 분석 결과이다. sleep 변수는 남자에서만... 기준이 되는 하루 8시간 수면에 비해 5시간 이하 수면인 경우 유의하게 비만 확률이 높았고, 그나마도 여자에서는 유의하지 않았다. 어쨌던 결과 양상은 J-shape 비스무레 하니 몇 년치 자료를 세로 결합하면 유의해질 지도 모르겠는데... 하여간 분석 전 기대했던 드라마틱한 결과는 나오지 않았다. 참 고질병인 게 잘 진행해오다가 더 이상 유의하지 않으면 진행하기 귀찮아진다. 먼저 주제도 그런 이유여서 중간에 주제를 바꾸기까지 했는데... 하여간 복합 표본 분석에 대해 쓰려는 포스트이니 마지막까지 힘내서 진행해 보기로 하자.
'R' 카테고리의 다른 글
복합표본자료분석 - 2½. EDA 도중에 포기한 예 (R) (0) 2019.12.19 복합표본자료분석 - 2. 자료준비 (R) (0) 2019.12.18 생존분석 (R) (2) 2019.11.15 로지스틱회귀분석 (R) (0) 2019.09.10 다변수분석법 (R) (0) 2019.09.07