-
의학 논문에서의 표 작성법의학논문작성 2019. 8. 4. 01:31
아마 하루에 발간되는 의학논문이 족히 수 천 건은 될 것이며, 저널 와치 같은 사이트에 가입되어 있으면 친절하게 내 관심분야에 대해 매주마다 수십 종의 논문을 메일로 보내 준다. 거기에 평소에 관심 가지던 (논문을 냈거나 앞으로 낼 예정인) 학술지에 실리는 논문들도 체크해야 하다 보니 이것도 하다 보면 중노동이 된다. 그러다 보니 꾀가 생기게 되는데 그 방법이
1) 우선 Abstract 읽어서 관심 분야인지 확인하고,
2) 연구대상 및 방법을 확인 한 다음,
3) Table을 확인해서 제대로 된 연구과정을 거쳤는지 확인한다.
이 과정을 무사히 통과해야 원문을 인쇄해서 천천히 확인한다. SCI급의 국외 학술지는 대개 이 과정에서 반 정도가 탈락하게 되며, 국내 학술지의 경우 탈락비율이 더 높아진다. 진짜 문제는 전공의들이 작성한 졸업논문인데... 전공의 졸업논문이 주로 실리는 국문 저널의 에디터를 몇 년 하다 보니 까다로왔던 부분이 점점 무뎌졌다. 아무래도 연구를 전업으로 하는 것이 아니고, 졸업논문이 생애 첫 논문이라 실수가 많을 수밖에 없는데, 그래도 연구방법론에 대해 어느 정도 교육되어 있어야 하는 것 아닌가라는 생각이 들어 블로그질을 하게 되었다.
연구 디자인을 편의 상 3가지로 분리해보면,
1) 탐색적 연구 디자인 (Explanatory research design)
2) 기술적 연구 디자인 (Descriptive research design)
3) 인과관계 연구 디자인 (Causal research design)
정도로 분류 가능할 것 같다.
1. 탐색적 연구에서의 표 작성
탐색적 연구는 "조사목표나 가설에 대해 명확한 이해가 부족한 경우 시행하는 연구"이다. "흔히 XX에 연관된 요소에 대한 연구" 등으로 이름 지어지며, 연구 극 초기 분야에 몇 개의 논문만 해당된다. 만약 "한국인의 당뇨 발생과 관련한 요소들"이라는 논문을 작성했을 때, 현재 2019년 기점으로 어떤 학술지에 제출한다면 결과가 어떨지... 아마 읽어보지도 않고 곧장 쓰레기통 행일 것이다. 그렇지만 주제 및 연구대상을 잘 잡으면 해 볼 만하기도 하다. 실제로 대부분의 학술지에 두세 달에 하나 정도는 실리기도 하고... 관심분야의 SCI급 학술지를 잘 보고 있으면 몇 달에 하나 정도 실릴 텐데, 만약 재현할 수 있다면 빨리 연구해서 제목에 "in Korea" 붙이면 국내 학술지에 투고 가능하기도 하다. 잡설은 그 정도로 마치고 만약 내 연구의 디자인이 탐색적 연구 디자인이면 Table 1은 general characteristics에 대한 내용이 되어야 한다.
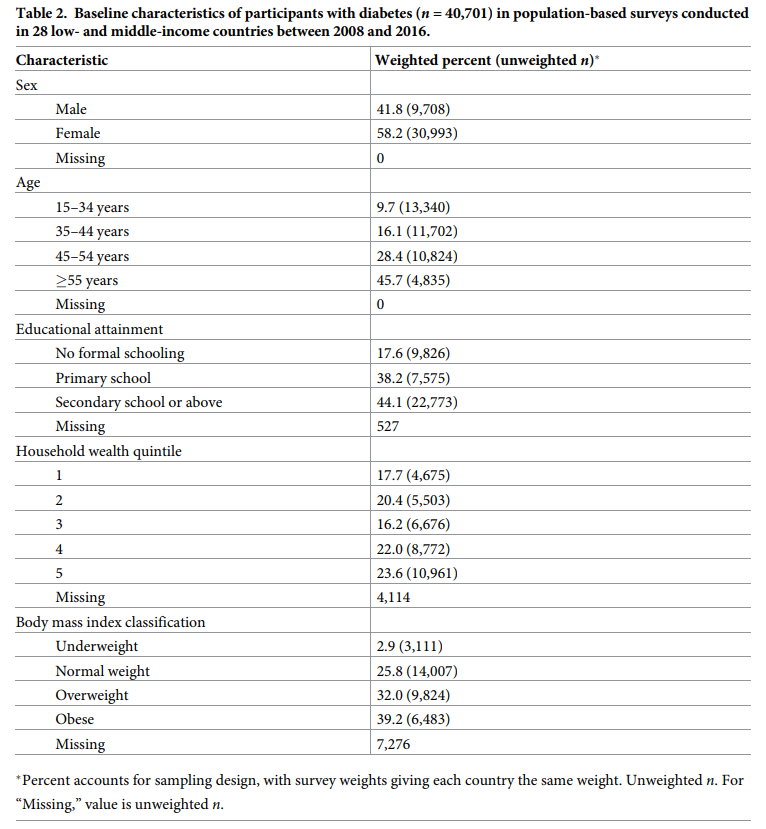
(그림은 Table 2인데... 논문마다 사정이 있으니 어느 정도는 이해해 주는 걸로 하고...) 예제는 중 저소득 국가에서 당뇨 관련 건강정책의 효과에 영행을 미치는 요소에 대한 연구이다. 탐색적 연구는 쉽게 말하면 "이전에 관련된 연구가 없으니 어떤 게 관련 있나 한 번 확인해보자."라는 의미이다. 확인하려면 연구 대상자의 분포를 표 1로 보여줄 필요가 있다. 그리고 보면 알겠지만 표 1에 p-value 같은 거 없다. 탐색적 연구이니 비교할 대상이 필요 없으며, 그냥 연구 대상의 숫자 및 퍼센트를 펼쳐 놓는 것으로 충분하다.

(자꾸 표 1이 아닌건 넘어가고...) 하여간 탐색적 연구의 표 1 작성은 general characteristics of participants로 시작하며, 표에 꼭 p-value를 이용한 군 간 비교는 필요 없다 정도로 이해하면 될 것 같다.
그 후에는 특별한 법칙은 없으나, 대개 단변수 (Univariate) 분석 결과와 다변수 (Multivariate) 분석 결과를 제시하는 것이 합리적이다.

위의 논문은 단변수 결과 없이 다변수 결과만 제시한 논문인데, 대개 큰 저널에 실린 논문들이 단변수를 생략하는 일이 많다. 그렇다고 그걸 따라 하면 안 되는 게 1) 예제 논문은 impact factor 12 짜리 논문이다. 여기 논문 낼 정도 사람들이 단변수/다변수 분석을 못할 거라고 아무도 생각하지 않는다. 하지만 여러분은... 어디서 본 건 있어서 졸업논문에 단변수 결과 생략한 채로 내는 논문들이 있는데... 솔직히 결과를 신뢰할 수 없다. 2) 그리고 이런 논문에서 단변수 결과가 빠지는 이유는 꼭 필요한 표랑 그림이 여러 개 있어서 표랑 그림 제한에 걸리기 때문이다. 근데 대개 졸업논문은 general characteristics (표 1), 단변수 결과 (표 2), 다변수 결과 (표 3), 거기에 많이 무리하면 그림 하나 정도인데... 단변수 결과를 빼면 표 2개만 남는다. 그래도 논문인데 표 3개 정도는 있어야 하지 않을까 한다.
2) 기술적/인과관계 연구에서의 표 작성
기술적 연구는 탐색적 연구에서 어느 정도 윤곽이 잡힌 내용을 바탕으로 주제를 좀 좁혀 시행하는 연구이다. 대부분의 관찰연구가 여기 해당하며, 흔히 보는 "XX가 YY에 미치는 영향" 같은 이름을 가진 연구들이다. 인과관계 연구는 상관관계를 넘어 인과관계를 추론하기 위한 연구로 의학분야에는 RCT (Randomized Controlled Trial) 연구가 대표적이다 (상관관계와 인과관계는 연구에서 중요한 의미를 가지고 있다. 그 둘의 차이를 잘 모르겠으면 확인해보자.).
문제는 기술적 연구의 표와 인과관계 연구의 표 내용이 언뜻 보면 동일해서 많은 사람들이 이 두 가지 연구에서의 표 작성 및 해석에 어려움을 겪고 있다는 점이다. 우리가 실제 임상진료에 도움을 얻는 연구는 거의 대부분 대형 RCT 연구의 결과이다.

NEJM에 실린 RCT 연구의 표 1인데, 대상자가 연구에 참여하기로 결정되면 무작위 방식으로 intervention group과 controlled group으로 나누어 연구한 후 나중에 결과를 확인하는 방식이다. 이론적으로 RCT에서는 (부정 및 연구설계에 오류가 없다는 전제하에) intervention group과 controlled group은 연구의 목표가 되는 치료효과를 제외한 나머지 부분은 완벽하게 동일하다 (두 군간에 통계 비교도 하지 않는 대범함을 봐라^^.). 문제는 이런 RCT는 무지막지한 시간과 돈이 들어가는 이유로 RCT가 진행되기 전 까지는 관찰연구에서 evidence를 쌓아가야 하는데, 관찰연구에서는 표 1의 해석법이 다르다는 점을 종종 무시하고 넘어가는 일이 흔하다.
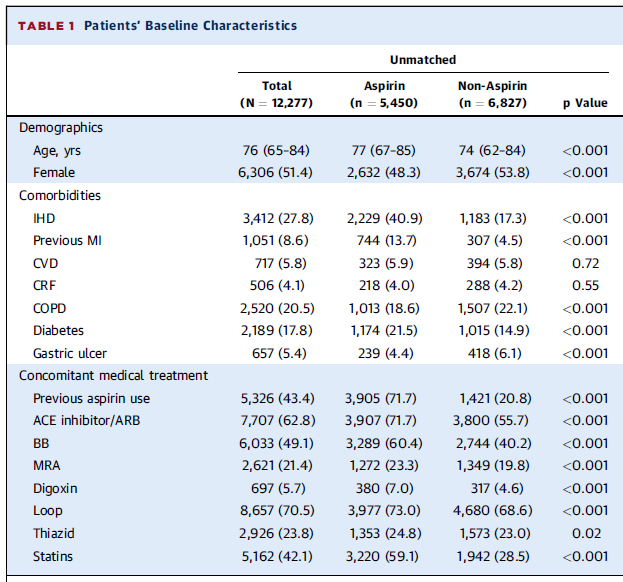
심부전 환자에서 아스피린 사용과 생존율의 관계에 대한 관찰연구이다. 표 1의 일부분인데, 아스피린 사용군과 아스피린을 사용하지 않은 군의 통계적인 차이는 명확하다. 거의 모든 항목에서 통계적으로 차이를 보이는데... 이건 두 집단이 다른, 이질적인 집단이라고 볼 수밖에 없다. 그게 무슨 얘기냐고?

숲 속 친구들의 BMI와 수명의 관계에 대해 연구하고 싶어 졌습니다. 친구들을 모아보니 쥐와 코끼리 밖에 없긴 했는데 별로 중요한 건 아니니 그냥 넘어가고... 하여간 연구를 했고, 성별, 소득 수준, 거주지, 최종학력, 동반질환 등을 covariates로 보정한 후에도 고 BMI 군이 통계적으로 유의하게 긴 수명을 보였다....라고 한다면 납득 가능한가? 이 예만 보면 말도 안 된다고 하겠지만 그럼 위의 연구에서 보여준 표 1의 두 집단이 코끼리와 쥐의 예와 다르다는 근거는 어디 있는가?

관찰연구에서는 비교하려는 두 군의 대상자가 동일한 집단이라는 보장이 없다. 아스피린의 예를 봐도 아스피린을 복용하는 사람은 복용하지 않는 사람에 비해 뭔가 좀 더 건강이 안 좋은 사람이었을 가능성이 크다. 그걸 그냥 분석하면... 결과는... 하여간 이런 비극이 일어나지 않게 하기 위한 방법 중 하나가 성향 점수 매칭 (Propensity Score Matching) 기법이다. 위의 표도 매칭 이전 (Unmatched) 상태에서는 양 군의 통계적인 차이가 크다가, 매칭 이후에는 차이가 없어지는 것을 보여준다 (더 정확히 말하면 양 군에서 차이를 만드는 극단적인 대상자들을 제외한 것이다. 아스피린 사용자 5450명 --> 3840명, 비사용자 6827명 --> 3840명). 이렇게 두 군의 이질성과 관계된 대상자들을 제외함으로써 두 군은 비슷해질 수 있는 것이다.

이 논문은 참 친절하게 매칭 전 후의 통계치까지 제시했다^^. 결과가 보이는가? 결과가 꽤 많이 다르다. 거기에 이렇게 해준다 쳐도 흔히 언급되는 "Unmeasured Covariates" 문제가 남는다. 표 1의 변수는 대상자의 모든 정보를 담고 있지 않다. 위의 쥐와 코끼리 예제도 아마 변수 중에 "종족" 항목이 있으면 간단히 해결되었을 문제이다. 이 문제는 어찌 해결될 수 있는 문제는 아니며 관찰연구의 숙명 같은 것이다. 결국 진실은 RCT를 통해서만 알 수 있다.

다른 관찰 논문의 결과이다. 4집단을 비교한 연구인데 나이 제외하고는 집단 간의 통계적 차이는 명확하지 않다. 이렇게 한 두 변수에서만 통계적인 차이를 보이거나 중요하지 않은 변수들에서만 차이를 보이는 경우들은 propensity score matching 등의 특수한 기법을 쓰지 않고도 납득 가능한 결과를 만들어 준다. 하지만 위에 언급한 것처럼 거의 대부분의 통계치가 p-value <0.001 인데도 다른 조치 없이 그냥 진행한다면 그 결과는 신뢰할 수 없을 것이다.
여담으로 커피와 건강에 대한 얘기를 좀 해보자. 인터넷 뉴스 건강 항목을 보면 커피와 고혈압, 커피와 암, 커피와... 등 내용도 다채롭게 그리고 결과도 다채롭게 장식하고 있다. 오늘 뉴스는 커피가 건강에 좋다인데, 그 전 항목은 커피는 많이 마시면 해롭다이다. 이렇게 결과가 지 맘대로 인 이유가 있다.
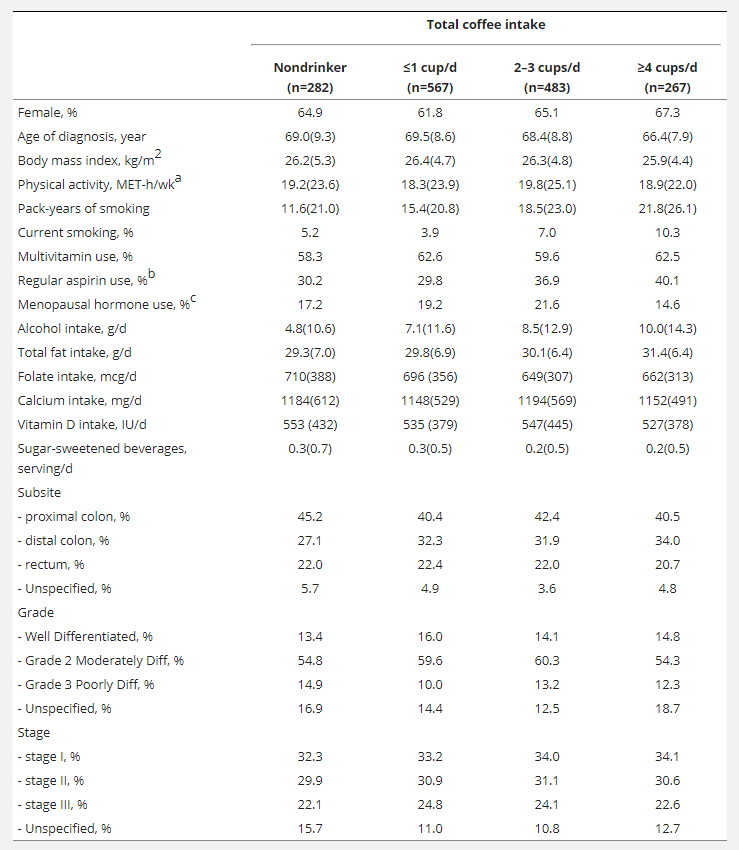
커피와 암 재발에 관한 논문에서 따온 표이다. 어디서 본 가락은 있어서 위의 NEJM 논문 에서처럼 관찰연구임에도 불구하고 군간에 통계 비교조차 하지 않았다 (내용을 보면 왠지 통계적인 차이가 있는 항목이 득실득실할 것 같다).

다른 예이다. 4군간의 통계적 차이가 명확하다^^.
이렇게 차이가 나는 집단을 Propensity matching 등의 추가적인 처리 없이 그냥 비교해 버리면 비극이 발생하게 된다. 그리고 그 비극의 결과가 지금 인터넷 건강 뉴스 항목의 댓글창이다. 사람들에게 혼란만 안겨주며 의학연구의 결과 자체를 믿을 수 없게 만드는...
사실, PSM을 한다고 혼란이 완전히 없어지지는 않는다. 결국 RCT를 해서 끝을 봐야 하는데... 누가 큰돈과 노력을 들여서 커피와 건강의 관계를 연구하겠는가?
네슬레, 동서?결국 시간이 지나도 결과는 제대로 나오지 않을 것이며, 이런 하품 질의 논문 결과들을 엮어서 메타 연구해봐야 결과도 똑같이 신뢰할 수 없을 것이다 (누군가 한 명언 중 하나가 쓰레기장에서 장미꽃은 피지 않는다이다 진짜 쓰레기장에 장미가 안 피는지는 모르겠지만...).'의학논문작성' 카테고리의 다른 글
복합표본자료분석 - 1. 기본개념 (SPSS & R) (0) 2019.11.19