-
복합표본자료분석 - 2½. EDA 도중에 포기한 예 (R)R 2019. 12. 19. 14:46
인터넷 뉴스를 보면 건강 관련 기사가 굉장히 많다. 그중에 일부는 의학이나 보건 관련 연구에 대한 기사이다. 최근 일부 기관에서 구성원들의 연구결과가 언론을 탄 경우 업적평가에 가산점을 주거나 심지어는 인센티브를 제공하는 경우까지 제공하는 경우가 있어서 이런 일들이 점점 더 늘어나는 추세이다. 근데 또 그중의 상당수는 국건영과 같은 공개자료를 이용한 연구이다. 앞에서도 계속 언급했듯이 이러한 공개자료를 사용하는 경우 자료 수집에 드는 노력과 비용을 아낄 수 있으며, 개인적인 노력으로는 국건영과 같은 한국인을 대표하는 자료를 얻을 수 없다는 장점이 있다. 그 반면에 자료에 대한 충분한 이해 없이 공장에서 찍어낸 듯한 저 퀄리티의 연구결과가 난립한다는 점은 오히려 국민건강과 전문가에 대한 국민의 신뢰도를 떨어뜨릴 수 있는 문제이다. 그리고 저자 입장에서의 단점 중 하나는 누구나 내 연구결과를 재현할 수 있다는 것이다. 이 글을 작성하는 저자 본인도 여기에는 뭔가 많이 아는것 같고 잘난 듯이 글을 적고 있지만 연구 초기의 논문을 보면 예전의 일기장을 보는 듯한 부끄러움이 넘쳐난다.
더욱이 국건영 같은 경우 상당수의 동료(peer)들이 자료 및 변수에 대해 어느 정도 파악하고 있어서 누가 한 연구결과를 발표하면, 예전에 내가 이 부분 볼때는 이런저런 한계점이 있었는데 이 연구에서는 그런 한계점을 어떻게 처리했을까? 라는 생각이 자연히 들게 되며, 만약 그런 부분이 제대로 처리되지 않은 것이 보일 경우 나머지 내용은 신뢰하지 않는다. 심지어는 재수 없으면 모 연구처럼 팩트체크 방송의 주제가 되기도 한다. 연구를 처음 하는 초보자의 경우 어딘가에 내가 쓴 글이 내 이름과 함께 평생 남아서 검색되며 심지어는 그게 방송이나 언론을 통해 돌아다닌다는 것의 심각성에 대해 잘 이해하지 못하는 경우가 많은데... 만약 본인의 연구결과에 확신이 없다면 교신저자의 탐욕을 제어해야 한다. 그게 안되면 평생 그 잘못이 내 이름과 같이 갈 수 있다.
쓸데없는 잡설이 길었는데... 위에 언급한 대부분의 재앙이 사실은 EDA만 충분히 했어도 예방 가능하다. 총 분석시간의 70% 이상을 EDA에 할애하는 것이 옳다. 문제는 복합표본분석의 경우 아무래도 할 수 있는 분석에 한계가 있어 마음대로 EDA를 할 수 없다는 단점이 있다. 저자도 이 부분을 어떻게 할까 고민을 거듭했는데... 결론은 EDA까지는 일반분석을 이용하고 본 분석은 복합표본분석을 하면 된다는 결론을 얻었다. 일반분석 결과와 복합표본 분석의 결과는 정확히 일치하지는 않지만 거의 비슷하다. 논문에 직접적으로 들어가는 내용이 아니라 참고하는 내용이라면 약간의 오차는 큰 문제를 일으키지 않는다. 그리고 만약 일반분석 결과와 복합표본분석결과가 서로 반대라면 뭔가 오류가 있거나 통계적으로 유의한 쪽이 type 1 error일 가능성이 있기 때문에 자료를 더 추가하는 등 좀 더 세심한 분석 후에 결과를 발표하는 것이 낫다. 결과를 늦게 발표하거나 안 하는 것이 잘못된 결과를 발표하는 것보다 낫다.
1. 예제선정 & 가능성 타진
인터넷 뉴스에서 국민건강영양조사라는 항목을 검색하니 전자담배와 우울증에 대한 연구결과가 첫 페이지에 나왔다. 논문 원문을 찾아보니 전형적인 졸업논문인데, 연구 초보자들이 할 만한 실수가 가득한 연구여서 예제를 삼기에 적당해 보여 이를 선정하였다.
이 논문의 주제는 전자담배흡연경험과 우울증상과의 관계이며, 따라서 이의 인과관계는
X: 전자담배 흡연경험 → Y: 우울증상
이 될 것이다.
이 연구에 필요한 변수들을 다시 정리하면,
X: 전자담배 흡연경험,
Y: 우울증상,
그 외 covariates ... 가 될 것이다.
이 부분 까지는 아직 아이디어 발상의 단계이다. 아이디어를 얻는 방법은 여러 가지가 있지만 가장 현실적인 방법은 해외 학술지 연구를 참조하는 방법이다. 관심 있는 주제의 권위 있는 해외 학술지를 읽다 보면 limitation으로 언급되는 부분이 존재한다. 이 부분에 대해 보완이 가능하다면 충분히 독창성을 지닌 연구가 가능하다. 하지만 국건영과 같은 개방형 데이터의 경우 공개되자마자 서두르지 않으면 얼마 지나지 않아서 관련 연구들이 발표되는 경우가 많아서 이 부분은 약간 힘들고, 대개는 해외 학술지에 발표된 내용이 한국인에게도 동일하게 적용되는지 확인하는, 흔히 말하는 in Korean 연구가 주를 이루게 된다.
아이디어를 찾았으면 그 아이디어가 내가 가진 자료로 현실화가 가능한지 확인이 필요하다. 주요변수들이 (특히 covariates) 빠진 자료를 이용한 연구는 신뢰성이 떨어지게 된다. 그리고 어떤 covariates들을 연구에 포함시켜야 되는지 기준은 비슷한 연구주제를 다룬 해외 학술지 발표 논문들이다.
초보자일수록 하기 쉬운 실수인데, 타 논문 인용에 굉장히 인색하다. 연구는 혼자 하는게 아니라, 기존에 많은 연구들에 한 마디를 보태는 것이다. 그러려면 내가 하려는 한 마디를 제외한 나머지 부분들은 가존 연구들과 동일해야 한다. 당연히 보정할 변수들도 기존 연구들과 어느 정도 동일해야 타 연구들과 비교가 가능하며 내가 하려는 한 마디가 납득 가능해진다. 만약 그런 과정이 없다면 내가 하려는 한 마디마저도 공염불이 된다. X나 Y같은 주요 변수가 없는 경우에도 연구를 계속하려는 사람은 없을 테니... 만약 동일한 주제를 다룬 해외 논문에서 지속적으로 다루는 covariate가 내 자료에 없다면 그건 연구의 현실성이 없는 것이니 포기하고 다른 주제를 다시 찾는 게 맞다(만약 없는 변수가 그리 중요하지 않은 변수라면 limitation에 포함시키면 된다). 그러려면 연수 첫 단계는 당연히 다른 논문들을 찾아서 그 논문들에서는 어떤 변수를 어떤 방식으로 다뤘으며 결과가 어떤지에 대한 파악이 필요하다.
2. 변수 확인
1) Y변수: 우울증상
PHQ-9변수를 다루는 방법은 이전 포스트에서 다룬 바 있다.

국건영의 PHQ-9 설문은 위와 같은 설문지로 이루어졌으며,

설문은 소아와 청소년에게는 시행되지 않았다(당연히 연구대상은 성인으로 국한될 수밖에 없다.).
PHQ-9 설문은 2016년 국건영에서만 이루어진 설문이기 때문에 세로 결합은 원칙적으로 불가능하다.
2016년 국건영 자료 중 설문 자료를 hn16 dataframe에 저장한 후 PHQ-9 변수를 살펴보면,


전형적인 right-shifted 된 자료이며, 결측이 2389명(아마 대부분이 소아/청소년일 것이다.)이나 된다. 이전 포스트에서 PHQ-9 점수에 로그 씌워봐야 별 재미없는 것 보여 줬고... 복잡하게 가려는 맘이 없으면 두 집단으로 끊어서 로지스틱 회귀분석으로 가는 게 맞겠다. 원본 연구에서는 9/10으로 끊었으니 이번 예제에서도 그렇게 해보자.
그다음 고려할 부분이 기존 우울증 진단 및 치료 중인 대상자를 어찌할 것이지에 대한 문제이다.



대상자 중 우울증 진단은 277명이 받았으며, 그 중 130명은 우울증 치료 경력이 있다. 만약 현재 우울증 약을 복용 중인 경우 우울증 설문만을 이용해서 우울증 여부를 가르는 것은 합리적이지 못하다.

우울증 진단을 받은 대상자 중 191명은 설문 당시 PHQ-9점수가 10점 미만이었으며, 현재 우울증 치료 중인 대상자 중 78명이 설문 당시 PHQ-9점수가 10점 미만이었다. 현재 우울증 치료 중인 상태이며 우울증 점수가 10점 미만인 사람을 어떻게 다루는 것이 옳을지는 저자의 결정이겠지만, 최소한 약먹어서 설문 지상으로는 정상화된 우울증 환자의 경우 어떻게 고민했고 어떤 방식으로 처리했는지에 대한 언급이 논문 내에 포함되어 있어야 한다고 생각한다.
원 논문에서는 이 부분에 대한 언급이 없는 것으로 보아, 이 부분에 대한 고민이 없었던 것으로 보인다. 별 것 아니라고 볼 수도 있는 부분이지만 국건영 자료를 다뤄본 적이 있는 연구자들은 이런 상황이 꽤 흔한 상황이며, 이런 부분에 대한 고민을 어떻게 했고 어떤 결정을 내렸는지에 대한 부분이 저자가 논문을 작성하면서 얼마나 공을 들이고 고민했는지에 대한 반영이라고 본다. 따라서 이런 세심한 부분에 대한 고민 혹은 배려가 없는 경우 그 결과물을 신뢰할 수 있다고 보지 않는다.
이번 예제에서는 우울증 점수 10점 이상 혹은 현재 우울증 치료중인 대상자를 연구 대상으로 삼아 진행하기로 했다(dep 변수). 그리고 19세 미만 대상자들은 연구대상자에서 제외하였다. 참고로 비슷한 예로 혈압약 먹는 대상자의 혈압 수치, 당뇨약 먹는 대상자의 공복혈당이 있다.
library(dplyr) hn16 <- hn16 %>% filter(hn16$age>=16) hn16$dep <- ifelse(hn16$mh_PHQ_S>=10 | hn16$DF2_pt==1, 1, 0)
2) X변수: 전자담배 흡연력
국건영에서 흡연에 관한 변수는 다음과 같다.


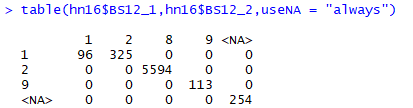
국건영 전자담대 관련 설문지를 보면 설문을 그대로 쓰기 힘든 몇 가지 이유가 보인다. 첫 번째는 전자담배 평생 경험자 중 오직 96명 만이 최근 1개월 내 전자담배 흡연 경험이 있다는 것이다. 대부분 전자담배 초창기에 한두 번 시도하다가 흡연자로 돌아간 사람들이 대부분 일 것이다. 마지막으로 전자담배 피운 게 1개월이 넘는 사람들을 전자담배 흡연자라고 부르기에는 뭔가 아쉬움이 남는다. 정확히 말하면 전자담배 경험자라는 것이 틀린 말은 아니지만 이 사람들을 전자담배 흡연자라는 명목으로 묶으면 안 된다고 생각한다. 대상자가 좀 적으면 어떤가? 예전에는 설문지 100장 돌려서 그거 가지고도 논문 잘 썼었다. n수를 부풀리기 위해서 연구결과의 신뢰를 어그러뜨리는 일은 해서는 안된다.

더 큰 문제는 이것이다. 전자담배 경험 설문은 그야말로 전자담배 경험을 묻는 것이고 현재 흡연과 병용하고 있을 가능성은 고려하지 않았다. 문제는 단지 18명만이 현재 흡연은 하지 않으면서 전자담배만 흡연하고 있으며 나머지는 담배를 매일 피우거나(71명), 가끔 피우는 (7명) 흡연과 전자담배 흡연을 같이 하는 사람이다.
원 논문에는 전자담배를 경험한 399명? (325+96=421인데... PHQ 설문을 안해서 뺐나?)을 연구대상으로 삼았는데... 아무리 예제라도 더 이상 이 연구를 따라갈 의미를 잃었다. 전자담배만 피우는 사람은 18명뿐인데 위의 표 내용을 알려주면 누가 연구 결과를 신뢰할 수 있겠나? 예제를 통해 비교하는 것도 어느 정도 큰 틀에서는 문제가 없다는 게 전제인데... 더 이상 의미가 없어진 것 같다.
이런 경우 복구하는 방법은... 연도 간 세로결합을 통해 n 수를 늘리는 것이다. 18*3=54, 54*2(case & control)이니 3개 연도 정도 합치면 얼추 100명 정도의 파워를 지니는 연구를 구성 가능하다. 문제는 Y변수인 PHQ-9이 2016년에만 측정되었기 때문에, 이 경우 Y변수 까지 바꿔야 한다.
연구 진행을 하다보면 이렇게 중간에 어그러지는 경우가 흔하다. 이렇게 망가진 부분이 보였을 때 정상적인 경우라면 보완을 하거나 아니면 다른 주제로 변경을 하는 것이 옳은 방법이다. 저자도 그런 측면에서 이 주제를 예제로 삼은 실수를 인정하고 다음에 다른 주제를 대상으로 다시 진행하는 게 맞을 것 같다.
'R' 카테고리의 다른 글
복합표본자료분석 - 3. EDA (R) (0) 2019.12.28 복합표본자료분석 - 2. 자료준비 (R) (0) 2019.12.18 생존분석 (R) (2) 2019.11.15 로지스틱회귀분석 (R) (0) 2019.09.10 다변수분석법 (R) (0) 2019.09.07