-
탐색적 자료분석 3-2. 두 변수의 관계 파악 - 연속 변수 vs 범주형 변수 (SPSS)SPSS 2019. 8. 28. 13:19anova.sav0.00MBt_test.sav0.00MB
이번 주제는 category 변수 형태의 독립변수와 연속 변수 형태의 결과변수의 관계를 분석하는 것이다. 본 주제로 들어가기 전 우선 t-test와 anova에 대해 정리하고 넘어가 보자.
1. 두 군의 평균 비교
어떤 두 그룹을 비교한다고 해보자. 예를 들어 남학생과 여학생의 성적을 비교한다고 해보자. 성적을 비교한다는 것은 어떤 의미일까? 한 명 한 명의 성적을 맞대어 비교해야 하나? 통상적으로 통계분석에서 뭔가를 비교한다는 의미는 "평균"을 비교한다는 의미이다. 평균을 비교하기 위해서는 평균이 어느 집단을 대표할 수 있는 수치가 되어야 하며, 분포가 "정규분포" 하는 것이 그 시작이다. 다시 정리해보면 우리가 사용하는 대부분의 통계기법은 평균의 비교이며, 이게 성립하기 위해서는 정규분포 해야만 한다.
자. 그럼 정규분포하는 두 집단이 있는데 한 집단은 평균이 0점이고, 다른 집단은 평균이 10점이라고 하자. 과연 두 집단은 차이가 있을까? 점수 차이가 있기는 한데 뭔가 좀 부족한 것을 느낄 것이다. 10점 차이가 어느 정도의 차이인지 모르기 때문일 것이다. 그 차이를 알려주는 것이 "표준편차"이다.

위 그림의 검은 선의 분포는 평균 0, SD=2이며, 붉은 선은 평균 10, SD=2이다. 표준편차에 대한 정보가 있으니 비교하기 좀 더 쉬워졌을 것이다. 자 다시 정리해보자. 두 집단의 비교란 평균의 비교이며, 평균의 비교를 위해서는 정규 분포하고 분산(표준편차의 제곱)의 정보가 있어야 한다. 이를 이해하면 t-test의 이해가 쉬워진다.
첨부파일인 t_test.sav를 이용해서 t-test를 시행해 보자.
분석 > 평균 비교 > 독립표본T검정 검정변수에 "x1", 집단변수에 "x2", 집단정의 > 집단 1: "1" 집단 2: "2"
제일 먼저 확인할 부분은 붉은색으로 표시된 Levene의 등분산 검정 결과이다. 위에서도 언급했듯이 평균을 비교할 때 평균의 수치만으로는 이게 얼마나 차이 나는 것인지 알 수 없다. 따라서 자료가 펼쳐 저 있는 정도 (분산 = 표준편차^2)까지 알아야 비교할 수 있다. 그 과정에서 두 집단의 분산이 같은지? 다른지? 가 의미를 가지게 된다. 그리고 이걸 확인하는 법이 등분산 검정 결과이다. Levene 등분산 검정의 p-value는 0.984 (>0.05)이니 "등분산이 아니라고 말 할 수 없다."
근데 사실 개별적인 검사 수치가 큰 의미를 지닌다고 생각하지는 않는다. 계속 언급하는 내용이지만 논문 통계의 목적은 다변수 분석이며, 다변수 분석을 위해서는 정규성과 등분산이 기본이다. 단변수 분석에서는 정규성과 등분산 만족 못해서 다른 방법 썼는데 그 후에 다변수 분석합니다^^ 도 말이 안 되는 얘기고, 단변수 분석에서 정규성과 등분산 만족 못해서 다변수 분석 안 가고 이만 접습니다^^ 도 똑같은 얘기다. 사전 분석에서 개별 변수의 정규성 확인하고 변환해 놓으면 어지간해서는 등분산도 크게 어그러지지 않는다.

박스 플롯을 통해서도 등분산을 확인 가능하다. 박스 플롯은 간단해 보이는 모양에 비해 많은 정보를 담고 있다. 위와 아래의 수염은 각각 4, 1 quantile, 박스의 위 와 아래는 3, 2 quantile, 박스 안의 굵은 선은 median이다. 굵은 선이 박스 안 가운데에 위치하며 위아래 수염 길이가 비슷하면 얼추 정규 분포하는 것 (최소한 skewness는 없는 것)으로 본다. 거기다 양쪽 그룹의 퍼진 정도가 비슷하면 얼추 등분산 한다고 볼 수 있다.
그럼 등분산을 만족한다 볼 수 있으니 위의 파란색 박스(등분산을 가정했을때의 결과)를 확인해 보자. 두 집단을 비교해 보니 group1(x2=1)의 평균은 -0.17, group 2(x2=2)의 평균은 10.13이며, 두 집단의 평균 차이의 95% 신뢰구간은 -11.03~-9.56으로 유의한 차이 (p-value <0.001)를 보였다.
2. 세 군 이상의 평균 비교
첨부파일 anova.sav파일을 열면, x1과 x2 변수가 보인다.
x1을 살펴보면,


Right-shifted 되어 있는 전형적인 의학연구에서의 변수이다^^. 왠지 히스토그램만 봐도 로그 변환해야 할 느낌이 오지만, 0 이 많기 때문에 그냥 로그 변환하면 안 되고 Yeo-Johnson 변환에 의해 log(x+1)해줘야 한다 (이해 안가면). 박스 플롯을 보면 위아래 수염의 길이가 제각각이다. 등분산이고 뭐고 이대로 분석하면 안 되는데...
로그 씌워서 다시 확인해보면,
변환 > 변수계산



박스 플롯도 좀 더 나아 보이면서, 수치들도 좀 더 좋아졌다. (이건 누누이 말하는 것이지만, 이런 사정을 이렇게 단변수 분석했을 때 처음 알게 되는 일이 있으면, 그건 사전 조사가 망했다는 의미다. 미리 로그 변환해놓고 '이럴 줄 미리 알았어'라는 식의 접근이 필요하다.)
anova 검정은
분석 > 평균비교 > 일원배치 분산분석 "사후분석" 항목에서 "Scheffe" 체크 "옵션" 항목에서 "기술통계", "분산 동질성 검정" 항목 체크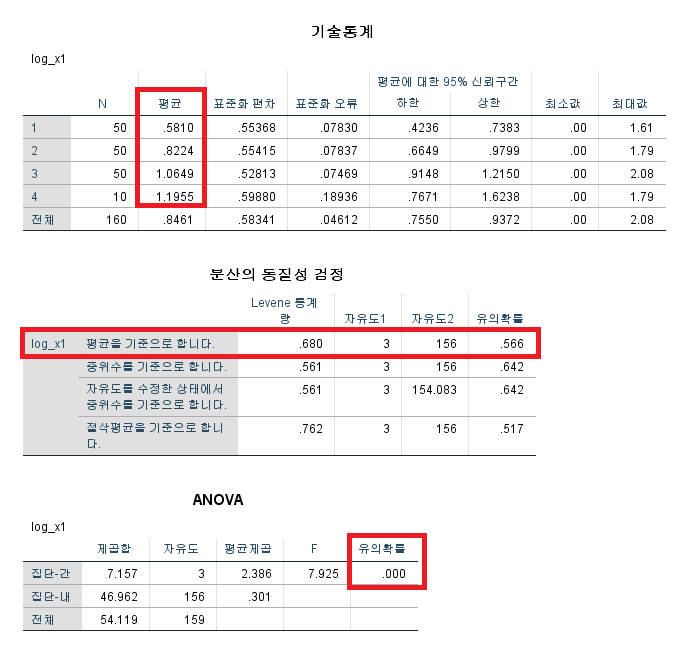
결과를 보면 x2=1 인 경우 log(x1+1)의 평균은 0.58, x2=2 인 경우는 평균이 0.82...이며, Levene의 등분산 검정 결과 p-value는 0.566 (>0.05) 등분산 가정을 만족한다. 세 번째 ANOVA 테이블은 anova 검정의 ANOVA 테이블이다^^. (일부러 소문자와 대문자로 쓴 거다.) anova 검정은 지금까지 본 것처럼 변수에 따른 평균의 비교에도 사용하지만 모형끼리의 비교에도 사용할 수 있다. 이번 모형은 log(x1+1)을 보는데 x2를 넣은 모형이니(model 2), 아무것도 넣지 않은 모형 (평균 모형, model 1)과 비교해서 통계적으로 유의하게 좋아졌는지 비교한 결과이다. ANOVA의 p-value <0.001이니 "변수 x2를 넣은 모형은 통계적으로 유의하게 나아졌다." 라는 의미이다.
자 그럼 p-value도 유의하게 나왔고.... 차이가 있네. 하고 끝내기에는 뭔가 좀 이상하다. x2는 4집단으로 되어 있는데 뭐가 어떻게 다르다는 건가? 그걸 확인하기 위해서는 사후 분석 결과를 확인해야 한다.

아까 사후검정 칸을 체크하면서 엄청나게 많은 방법이 있는 것을 봤을 것이다. 각각 다 다른 방법이고 장점과 단점이 있는 방법들이다. 그리고 결과도 다 다르다^^. 사실 anova 결과는 table 1이나 2 정도에 들어가는 내용이며, 논문의 주요 분석법은 아니다. 그렇기 때문에 극단적으로 말하자면 사후 분석법을 어떤 방법을 썼는지 관심 있어하는 사람은 없다. 그러니 의학계열에서 가장 일반적으로 흔히 보이는 Scheffe 검정법을 쓰면 아무도 뭐라 하지 않는다. 결과를 해석해 보면 x2가 1인 경우 x2가 3인 경우 및 4인 경우와 유의한 차이를 가진다 (붉은색 및 파란색 원). 이를 보기 쉽게 같은 집단으로 구분하면 x2가 (1과 2인 경우), (2, 3, 4인 경우) 두 개의 집단으로 나뉜다. 그리고 사후 분석법에 따라 결과가 극단적으로 달라진다. 결과가 애매한 경우 방법을 달리하면 원하는 결과를 얻을 수 있다. (다른 말로 하면 이상한 방법을 쓸 경우 원하는 값이 나올 때까지 돌렸다는 의심을 받을 수도 있다.)
3. GLM으로 분석
자꾸 언급하는 내용이지만 t-test나 ANOVA는 본 분석 전에 하는 간 보기 같은 느낌이지, 절대로 논문의 main이 되는 분석은 될 수 없다. 어차피 GLM으로 분석한 결과가 단변수 분석의 결과이니 확인하고 넘어가자.
분석 > 일반선형모형 > 일변량



일반선형모형은 선형 회귀분석 + anova 분석이다. 선형 회귀 분석 창에 비해 뭔가 선택할 부분이 많아져서 귀찮은 면도 있지만 다변수 분석에서 더미 변수를 만들 필요가 없다는 측면에서 아주 유용하다. 결과도 이전 anova결과와 같은데, Levene 검정 결과 확인하고 개체-간 효과 검정 창이 ANOVA 테이블이다. 모수 추정 값을 해석해보면, 절편은 1.20으로 x2가 기준(reference, x2=4일 때 log(x1+1)=1.20 이라는 것이다. 그리고 x2=1일때는 log(x1+1)=(1.20-0.61= 0.59), x2=2일때는 log(x1+1)=(1.20-0.37= 0.83)... 그리고 x2 변수 옆의 p-value는 x2가 기준 (x2=4) 일때와 비교해 유의한 차이를 보이는지이다.
결과제시는,
Estimates SE p-value x2 1 -0.614 0.190 <0.001 2 -0.373 0.190 3 -0.131 0.190 4 Reference 정도로 한다. (변수의 개별 항목에 속한 p-value를 제시하는 경우도 있지만 anova 결과의 p-value 제시가 더 합당하다.)
4. Take Home Message
1) 두 집단의 비교는 t-test, 3 집단 이상의 비교는 ANOVA
2) 정규성과 등분산에 너무 목숨 걸지 말자.
3) ANOVA와 anova는 다르다.
'SPSS' 카테고리의 다른 글
다변수분석법 (SPSS) (0) 2019.09.07 탐색적 자료분석 3-3. 세 변수의 상호작용 (SPSS) (0) 2019.08.29 탐색적 자료분석 3-1. 두 변수의 관계 파악 - 연속변수 vs 연속변수 (SPSS) (0) 2019.08.26 탐색적 자료분석 2. 결측치 확인 및 처리 (SPSS) (0) 2019.08.05 탐색적 자료분석 1. 정규성 검정 (SPSS) (1) 2019.08.02